CAPTCHA adds friction
Good respondents pay the price, while determined attackers increasingly route around it.
Proof of Human continuously verifies behavior across surveys, panels, and high-stakes user flows. It helps teams catch bots, AI agents, and low-quality traffic while preserving completion rates and giving reviewers evidence they can actually use.
Held-out agent detection on the current benchmark set.
Share of legitimate users flagged incorrectly on the current held-out benchmark.
p99 scoring built for survey and onboarding flows that cannot tolerate delay.
Signals summarized into interpretable evidence instead of a bare score.
Watch how quickly a convincing bot can produce plausible answers, then see how Proof of Human surfaces the behavioral evidence static checks miss.
Buyers need confidence that detection claims hold up against the sophisticated sessions their current checks keep missing.
Detection has to stay fast and invisible, or it creates new friction, drop-off, and false positives for legitimate respondents.
Teams want proof that rollout is lightweight, platform-friendly, and realistic for live survey and panel operations.
Buyers are not looking for another blunt filter. They need a way to spot sessions that look acceptable on the surface but fall apart when you inspect how they were completed.
Good respondents pay the price, while determined attackers increasingly route around it.
They help at the edges, but they still create false positives and miss in-session behavior.
Open-end checks and row-by-row QA burn time exactly where fraud is getting harder to see.
AI agents can produce convincing outputs. The process underneath is where they still slip.
Cleaner data, faster review decisions, fewer missed fraud events, and less friction for legitimate users.
Behavior-based detection catches sessions that look polished in the final answer but break on process.
Prioritize the sessions that deserve attention instead of pushing every edge case into a human queue.
Give teams evidence they can point to when they need to trust, defend, or challenge the sessions behind a study.
Preserve the experience for legitimate users by keeping verification invisible during the session.
The value is not a mysterious number. Teams need a top-line recommendation plus enough evidence to automate confidently, review efficiently, and explain what happened when a session gets challenged.
See the mix of suspicious traffic entering a survey, route, or high-stakes flow in one interactive view.
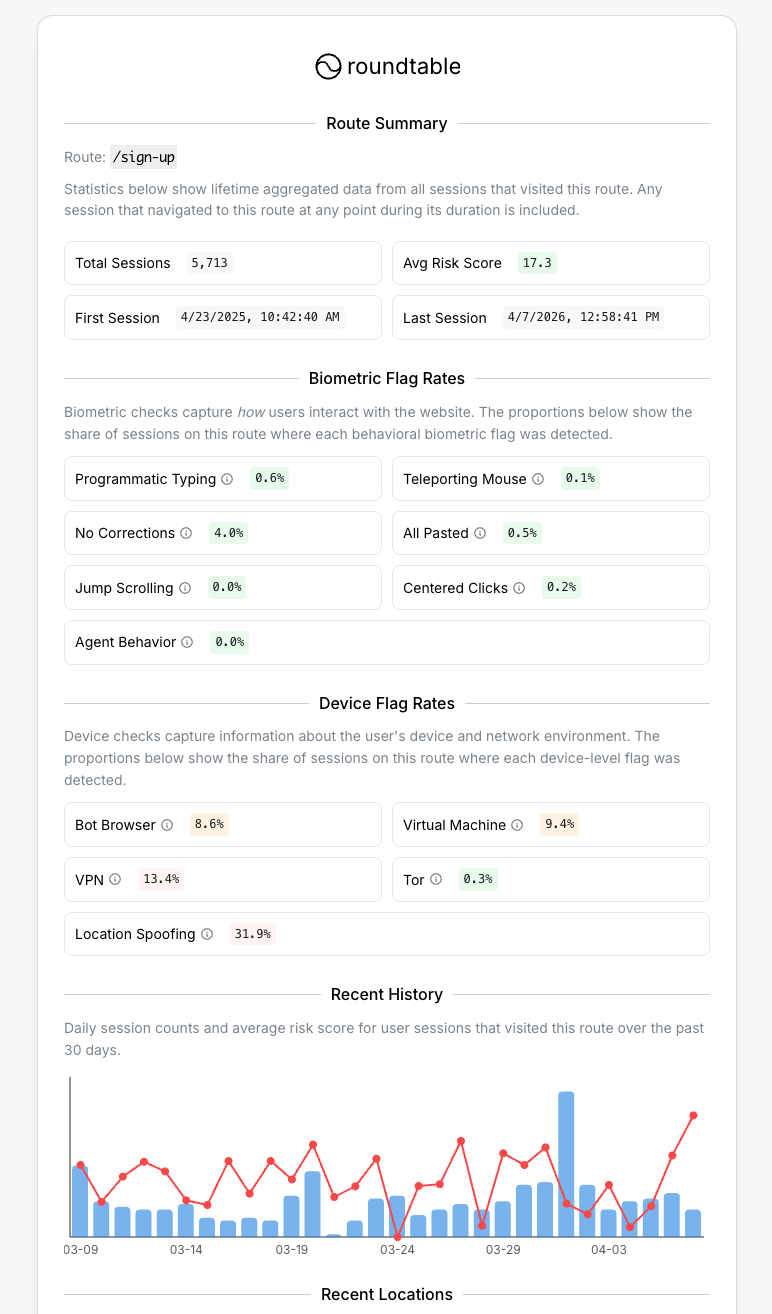
Track aggregate fraud patterns at the route level before they turn into bad data downstream.
Open route summaryTop-line score and recommendation for accept, review, block, or route decisions.
Visible reasons the session was flagged, not just an unexplained model output.
Concrete interaction history for reviewers who need to inspect how the session unfolded.
Playback and motion context that make suspicious behavior easier to understand quickly.
Structured output for analysts, suppliers, and post-field QA workflows.
Session-level fields that can be consumed in internal dashboards or decision systems.
Compare a flagged bot session against a human session in the same interface. Buyers can move from the score to the underlying evidence without guessing what the model saw.
See what normal hesitation, corrections, and navigation look like in a low-risk session.
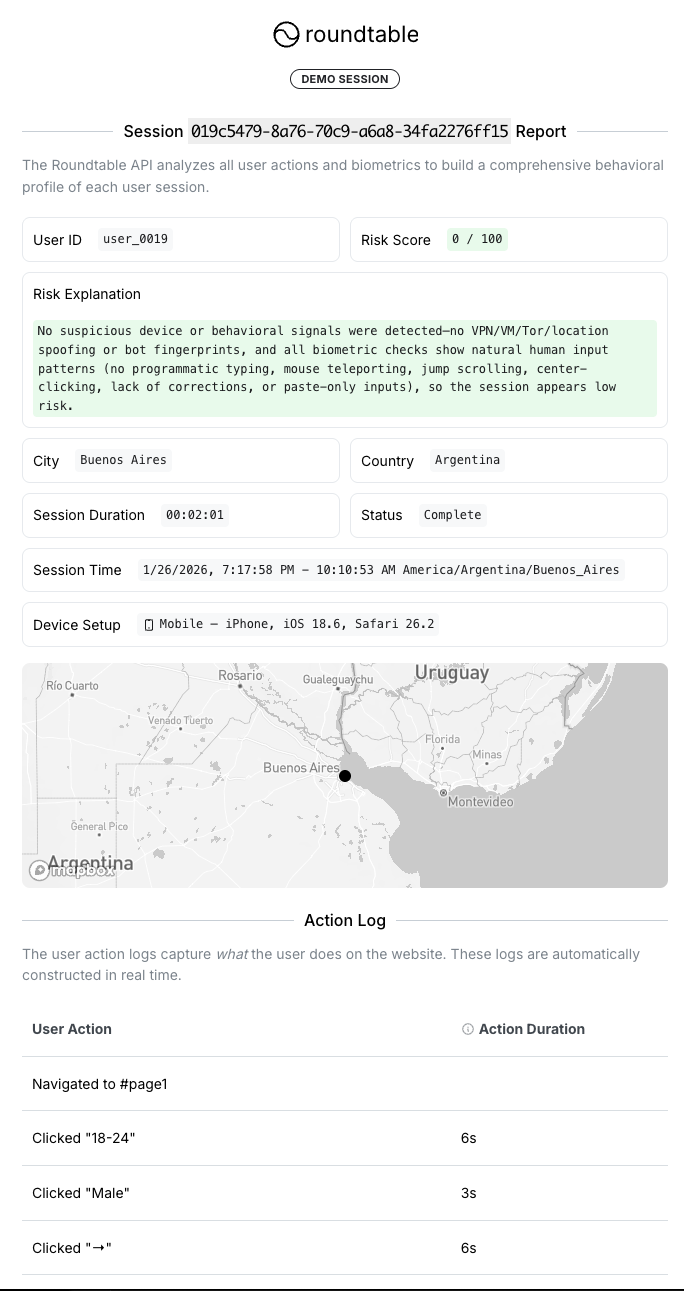
Open the full report to inspect the evidence in a dedicated tab.
Open human reportSee how suspicious typing, movement, and session behavior surface in a high-risk report.
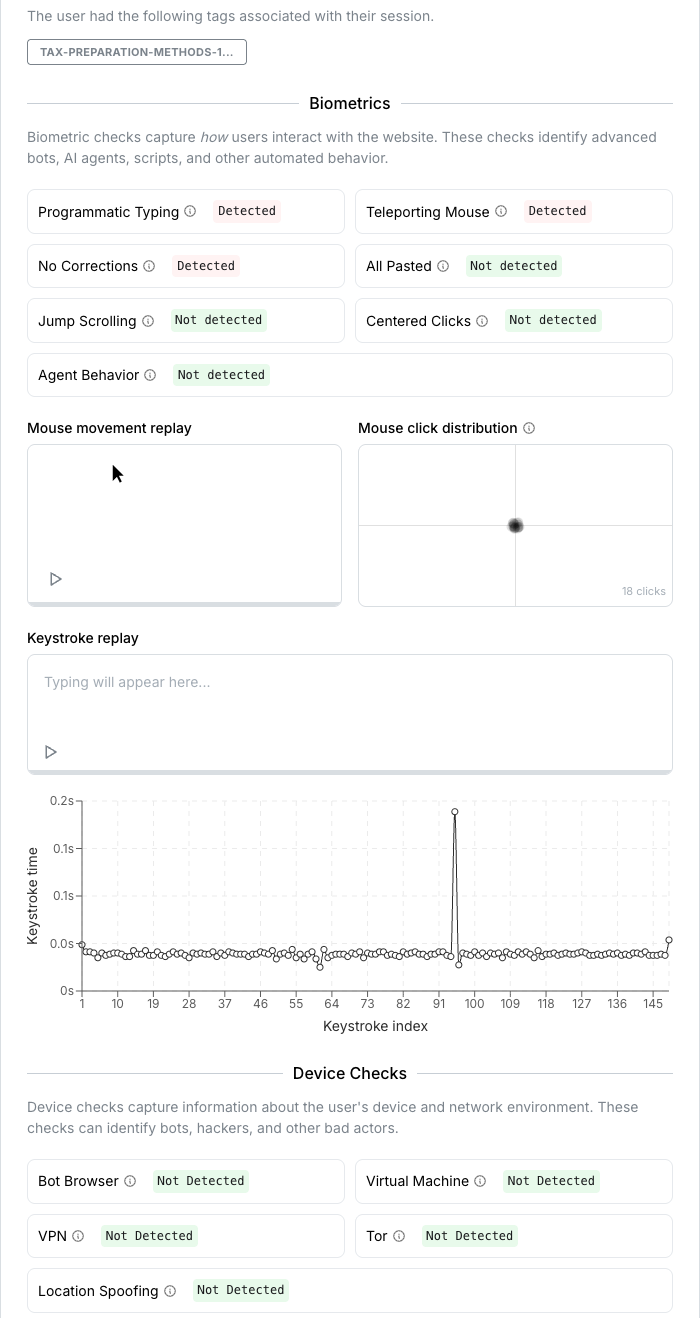
Review the same production evidence your team can use to justify a reject or escalation.
Open bot reportThe same evidence that drives review decisions in the product can be delivered to your own systems through exports and APIs. You are not forced to manage fraud from the dashboard alone.
Pass risk score, top flags, and supporting evidence into internal decision systems, QA dashboards, or supplier workflows.
{
"session_id": "sess_01JX4M0J8K1A4M7Y9QF3R2",
"risk_score": 93,
"risk_tier": "high",
"recommendation": "review_or_block",
"summary_flags": [
"programmatic_typing",
"teleporting_mouse",
"all_pasted"
],
"evidence": {
"paste_ratio": 0.94,
"corrections": 0,
"scroll_pattern": "jump",
"environment": ["vpn", "bot_browser"]
}
}Sort by risk, inspect top flags, and join route or supplier context without opening the session UI for every record.
| session_id | score | tier | top flag | route |
|---|---|---|---|---|
| sess_01JX4... | 93 | high | programmatic_typing | /survey/customer-trust |
| sess_01JX5... | 81 | review | all_pasted | /survey/concept-test |
| sess_01JX8... | 14 | low | none | /survey/brand-lift |
Proof of Human fits alongside the tools you already use. Add the script to a survey, panel, or web flow, then start collecting behavioral signals without interrupting legitimate users. The live dashboard brings route health, session reports, exports, and API-backed workflows into one operating surface.
Drop the script into a survey or web flow and begin collecting behavioral signals immediately.
<script defer src="YOUR_PROOF_OF_HUMAN_SDK_URL" data-site-id="YOUR_SITE_ID"></script>Users are never interrupted during the session, and teams can view sessions and risk scores live.
Filter by originating route or use tags to group traffic by campaign, survey, or product surface.
Ingest risk scores and behavioral signals directly into internal dashboards or decision systems.
Share from the app or download the data to produce transparent reports for clients and partners.
Final answers can look plausible. The process underneath still diverges. Compare humans, naive agents, and stealth agents performing the same tasks side by side before you look at the model that scores them.
The model is trained on verified human behavior and engineered agent runs, then evaluated on held-out data. The result is a score grounded in observed behavior, not guesswork, with benchmark coverage that reflects real interaction patterns and modern attack behavior.
The model is informed by benchmark data, real-world traffic patterns, and the risk thresholds teams use to decide when fraud is becoming operationally expensive.
Keeps legitimate respondents in flow by minimizing incorrect flags on good sessions.
Verified human behavior used to train and benchmark the model on real interaction patterns.
High recall against engineered agent behavior on the current held-out benchmark.
Engineered stealth and agentic-browser runs used to pressure-test the model against modern threats.
Mouse, typing, paste, scroll, click, timing, and environment signals summarized for scoring.
Production traffic gives the model and review workflows exposure to real fraud pressure at scale.
Reliability built for live survey, panel, and onboarding flows that cannot afford detection downtime.
Across live traffic, contamination can represent a meaningful share of incoming sessions when left unchecked.
Raw interaction data is transformed into behavioral features and fed into a gradient boosting model that learns to separate human sessions from engineered agent behavior.
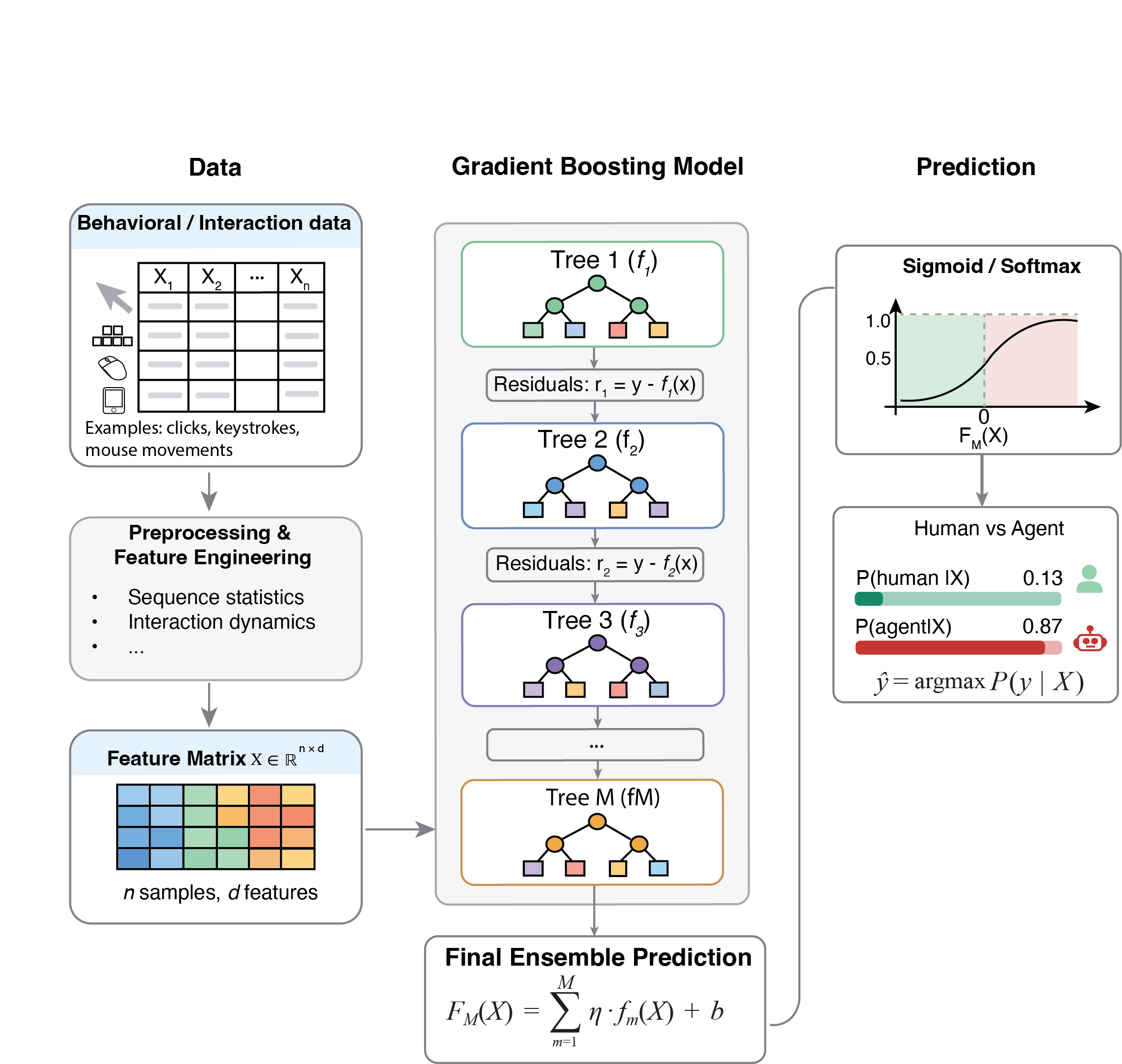
Teams get quick-read behavioral indicators up front, while the model evaluates far richer session telemetry underneath the score.
The current held-out benchmark shows a 0.2% false positive rate on legitimate users and strong agent detection at the same time.
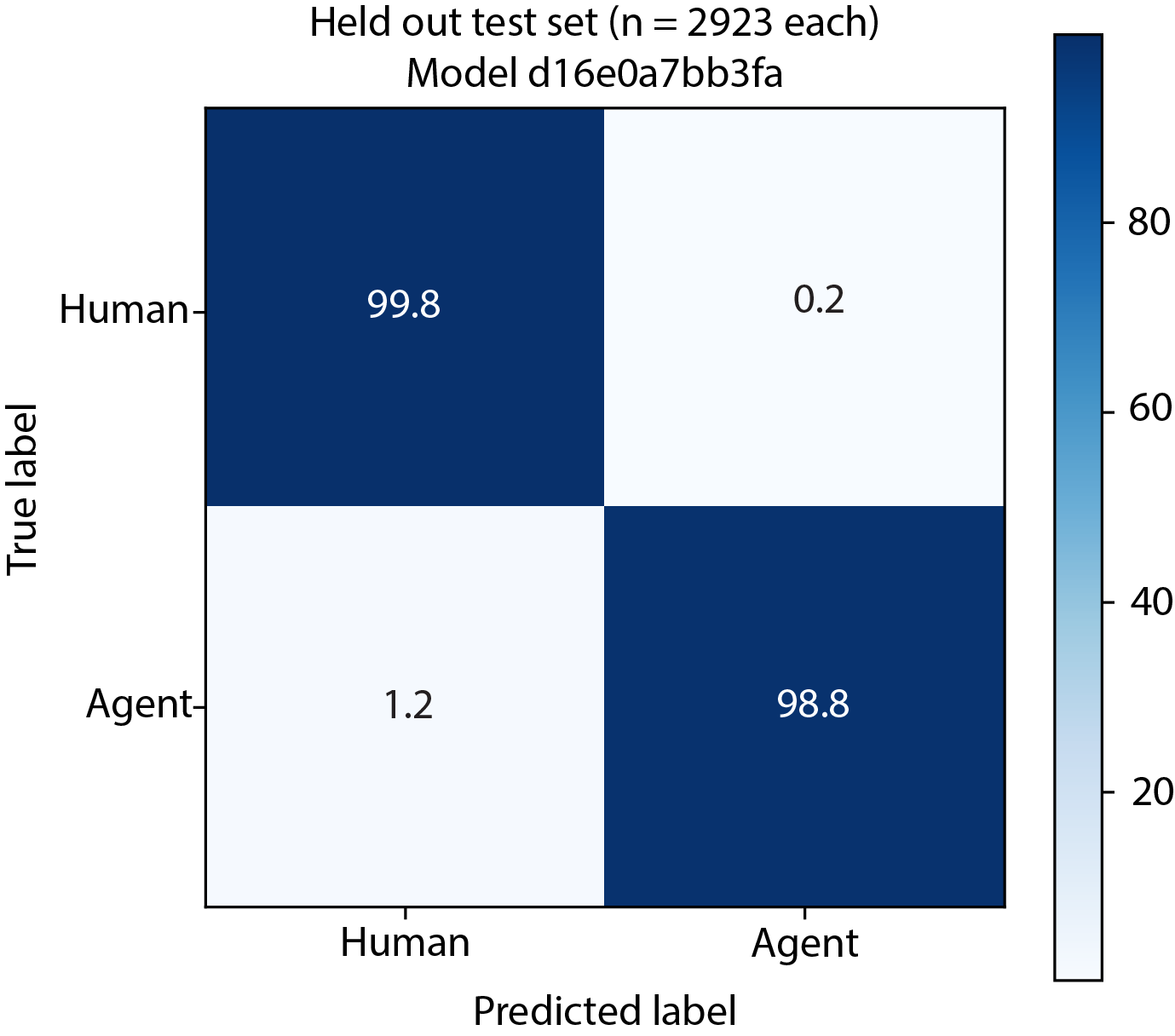
False positive rate
Agent detection
Overall accuracy
Score distribution matters because it shows separation across the session stream, not just performance at a single cutoff.
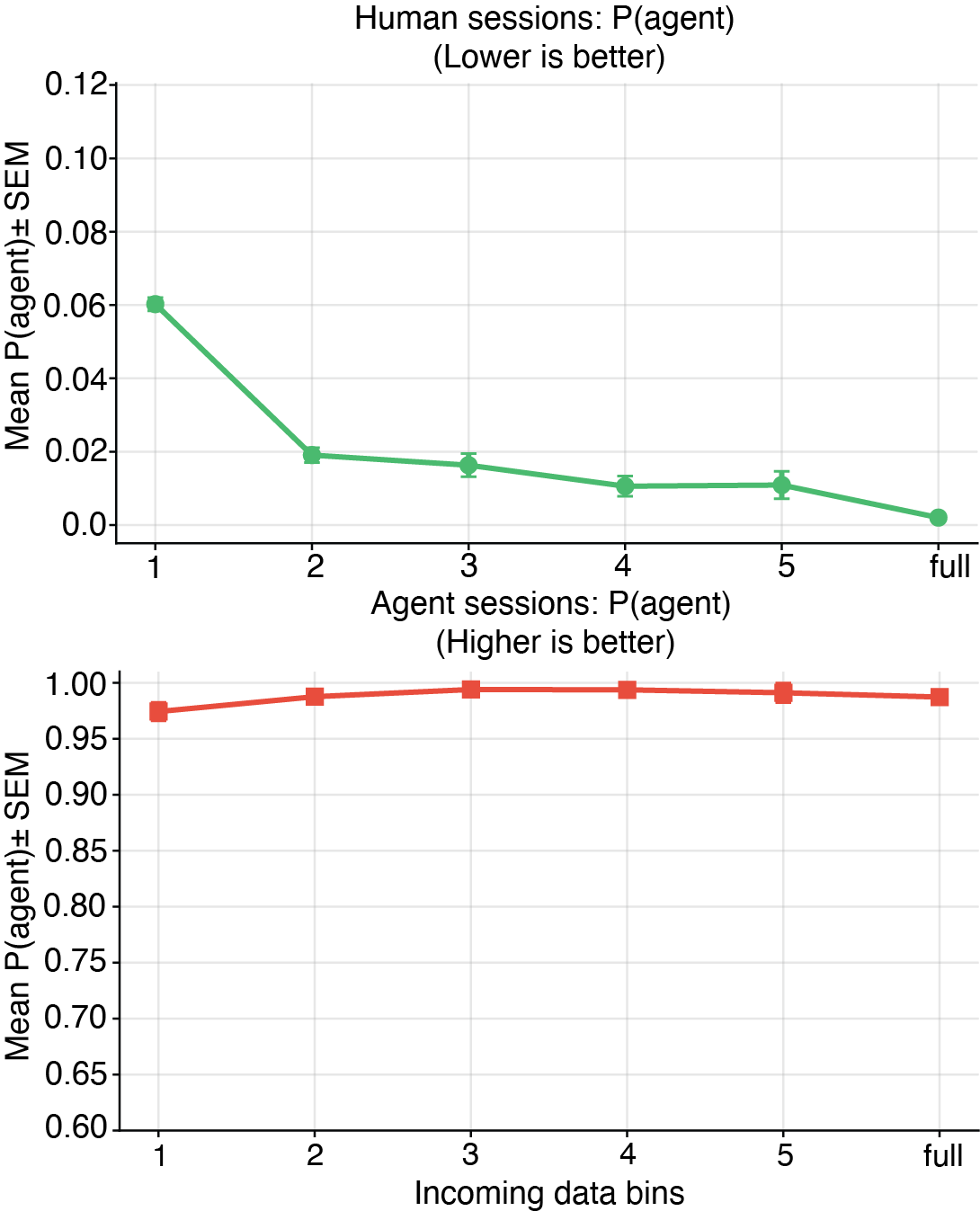
The research backs the core commercial claim: modern automation can pass surface-level checks, but it still leaves behavioral evidence behind.
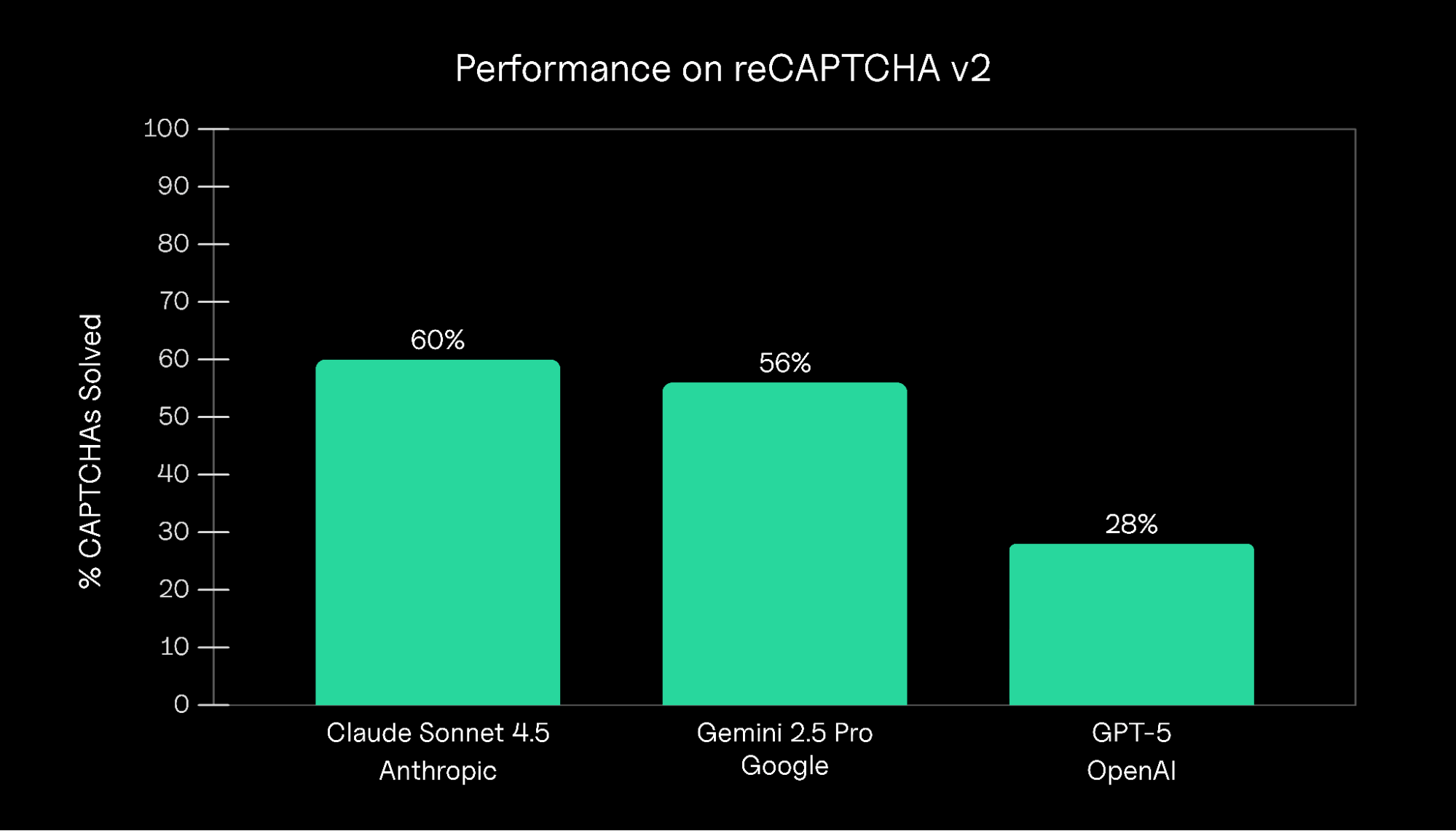
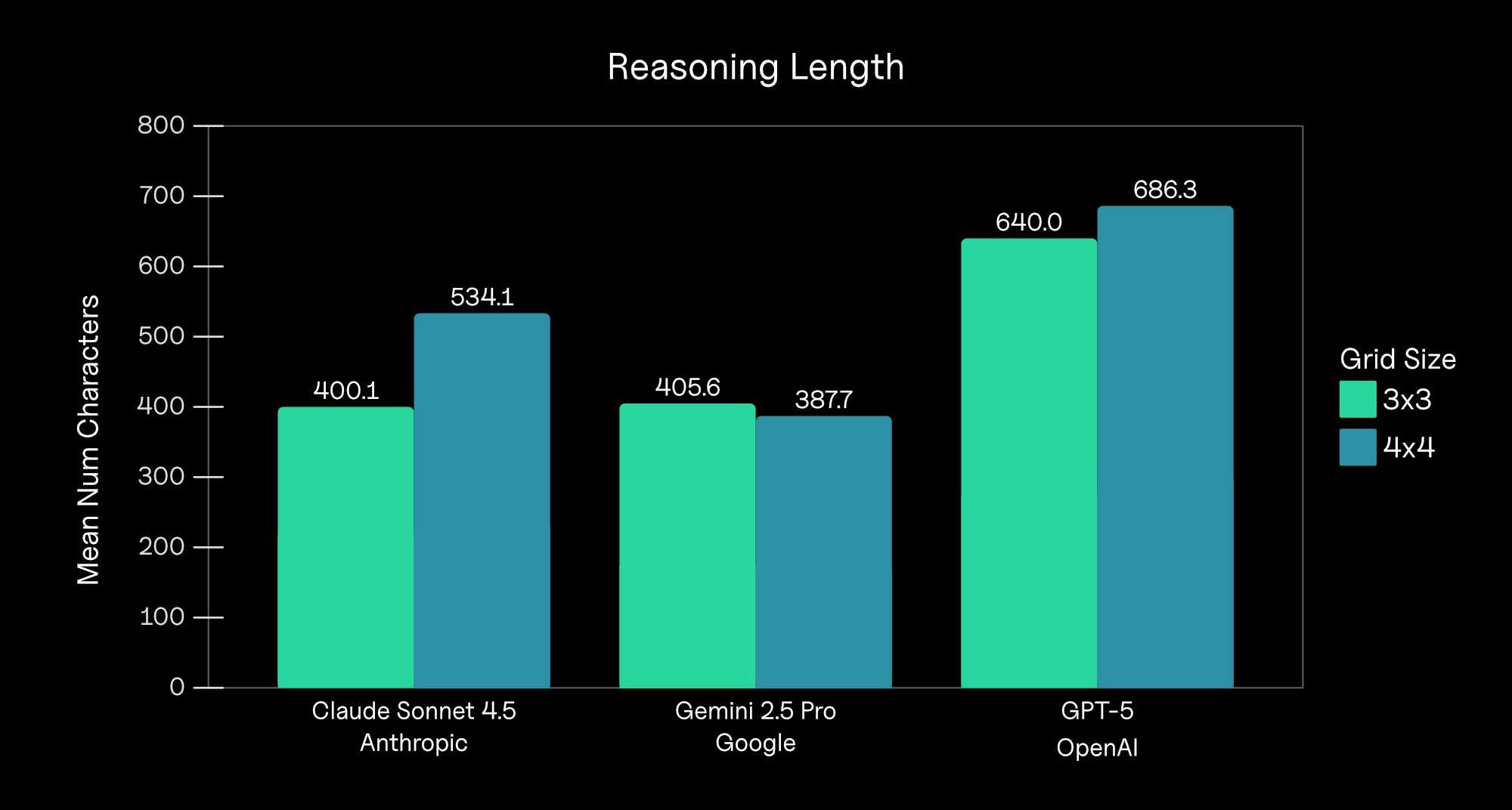
A closer look at why challenge-based defenses alone are no longer enough against modern automation.
Read paper →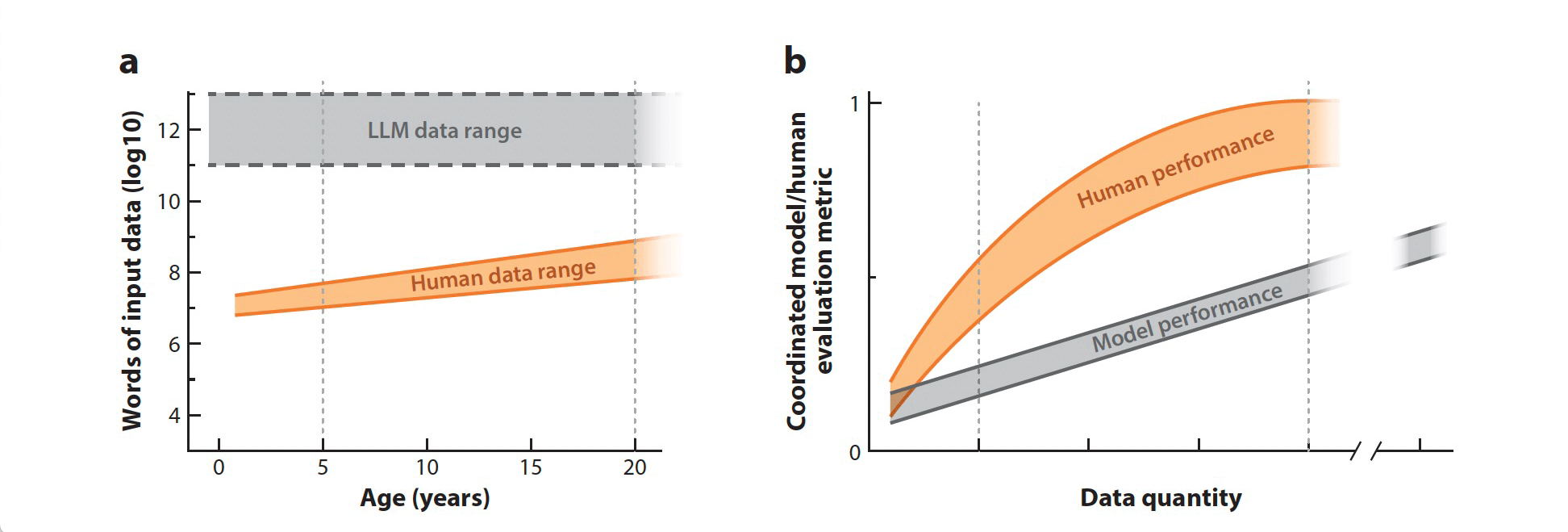
Plausible outputs do not guarantee a human process. That is why behavior-first verification matters.
Read paper →Run a pilot on live traffic and get a clear picture of the bots, agents, and high-risk sessions already reaching your routes.